
CIFAR10 Object Recognition
Jifu Zhao, 09 March 2018
CNN for Object Recognition in Images (case study on CIFAR-10 dataset)
Object recognition is a fundamental problem in computer vision. Even in a few years ago, it is still very hard for computers to automatically recognition cat vs. dog. But now, with the development of deep learning, especially Convolutional Neural Networks (CNN), this task is pretty easy. In this blog, using CIFAR10 dataset, I built two simple CNN models and try to recognition 10 different objects among a large amount of images. The whole project can be found in my GitHub: CIFAR10_Keras.
Dataset
The dataset I used is CIFAR10, you can check the details in the following link: https://www.cs.toronto.edu/~kriz/cifar.html. There are totally 50000 32323 RGB images in 10 classes: airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. The first 64 images is shown below.

In this project, followed some papers and some online resources, I implemented two commonly used CNN models: VGG and ResNet. All the models are trained on AWS with GPU speedup.
VGG
Pre-trained VGG16 and VGG19 are included in Keras, here, I build a VGG-like CNN models for object recognition. You can refer to the original papers for details: Paper.
1. Build VGG models
Check my Jupyter Notebook: CIFAR10_Keras
2. Visualize VGG model
Keras provides two very good ways to visualize your models, including keras.utils.print_summary() and keras.utils.plot_model(). Below is the screenshot of the output of model.summary()
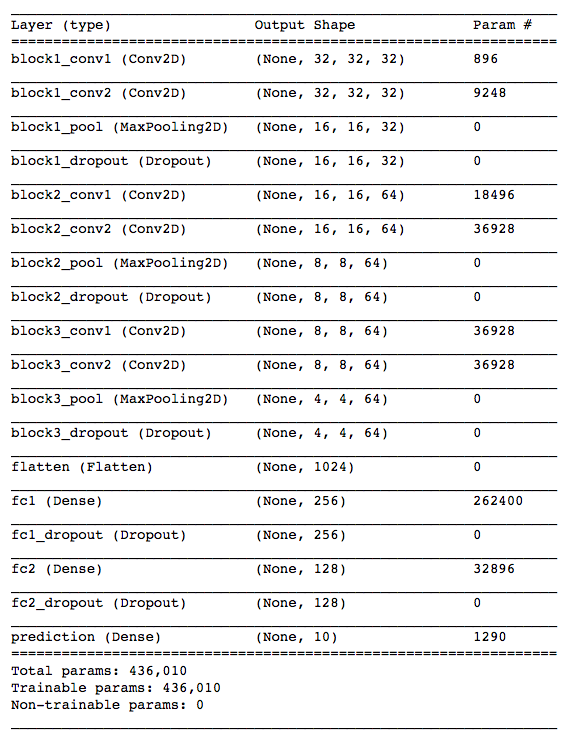
3. VGG loss and accuracy versus training epochs
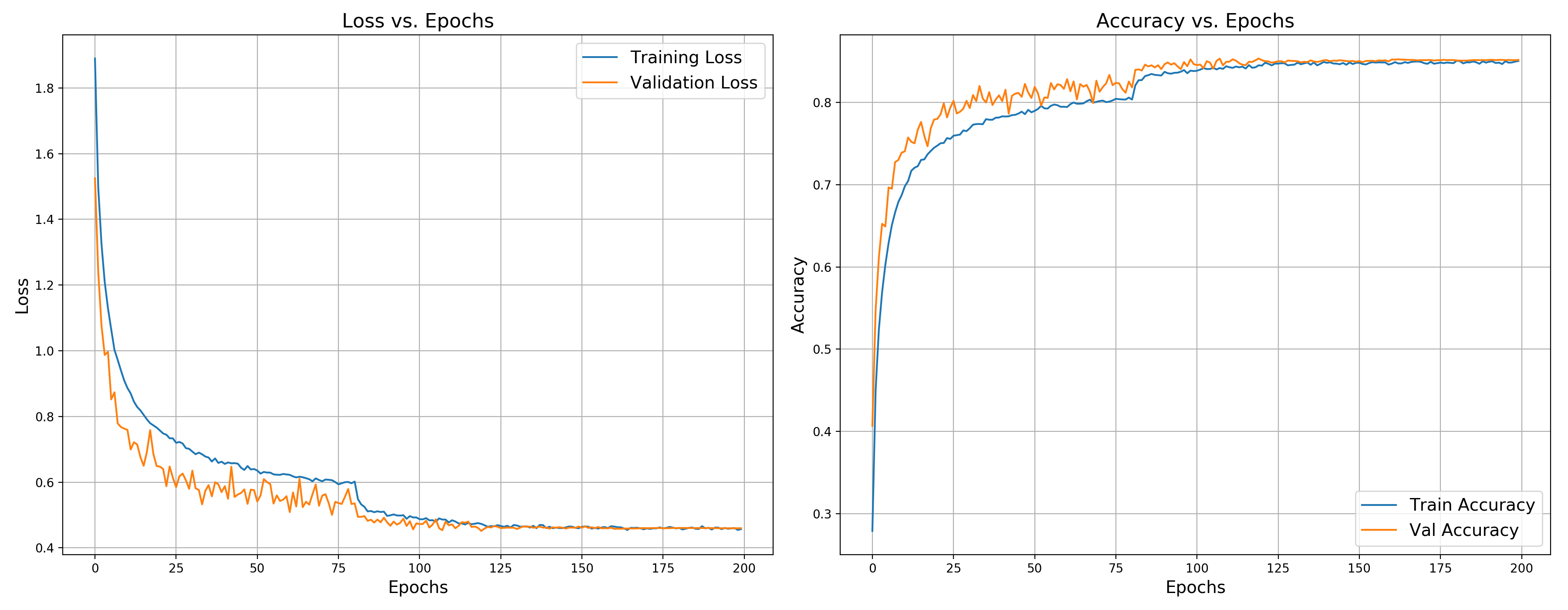
The training/validation loss and accuracy versus training epochs are shown below. After 200 epochs, the test accuracy is around 0.85290, which is still underfit.
ResNet
Keras already provides a very good example code for ResNet. Here, using the same structure, I re-implement the ResNet structure in my own way. For details, you can refer to the original papers Paper 1, Paper 2
1. Build ResNet model
Check my Jupyter Notebook: CIFAR10_Keras
2. ResNet loss and accuracy versus training epochs
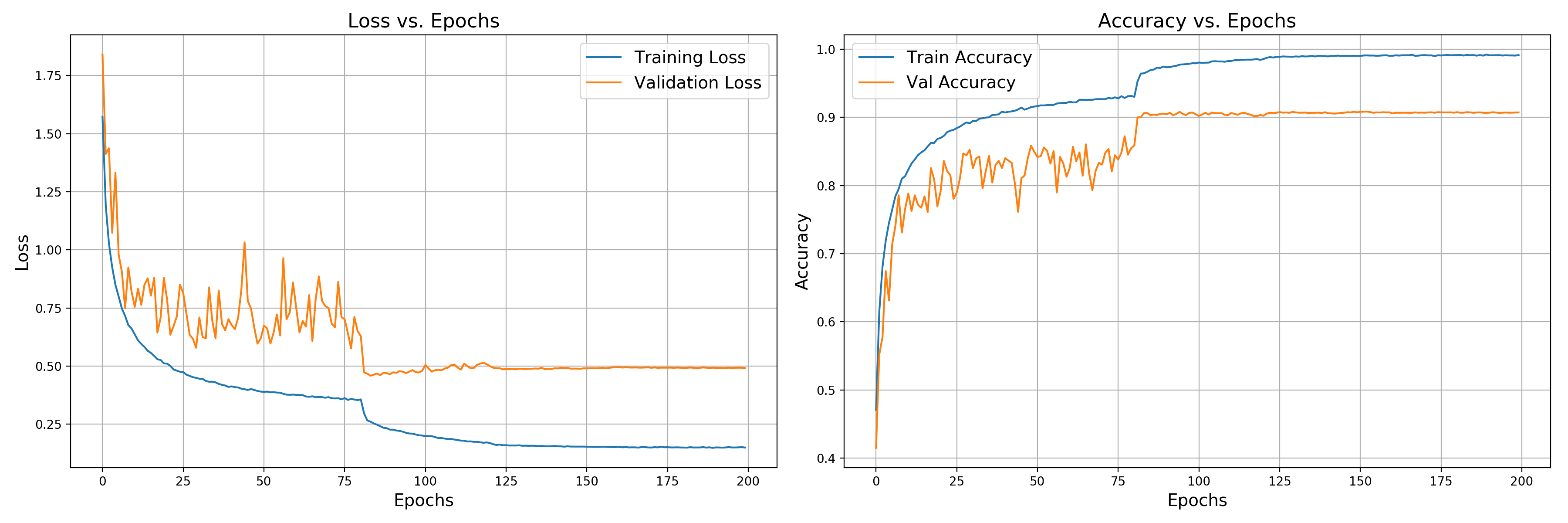
The training/validation loss and accuracy versus training epochs are shown below. After 200 epochs, the test accuracy is around 0.90840. Not a bad result, but the model seems to overfit a little bit. If you submit this result to Kaggle, your score will be among top 20 based on the historical data.
Note
I only implemented two relatively easy and small models, the performance is acceptable. To see the best performance, you can refer to the following link. Or, you can check Kaggle to see how people solve this problem link. For more details, please refer to my GitHub: CIFAR10_Keras